Building Arc Intelligence: Agentic AI For Complex Financial Analysis

Where we started
For many, 2023 will be remembered as the year the AI revolution truly took off. Advances in natural language processing and powerful generative models have unlocked a new technological era, sparking exploration across industries. This wave of innovation has produced countless tools aimed at streamlining workflows, with intelligent agents automating repetitive, time-intensive tasks.
However, as 2024 unfolds, we realize that AI adoption is more measured than most had expected, especially in industries with strict accuracy demands like finance. The initial excitement has given way to the realization that achieving impactful AI automation is challenging due to the standards required for accuracy and reliability.
We believe the cold-start problem is central to this slower adoption: in industries where the cost of making mistakes is high, users are hesitant to adopt automation unless the accuracy is near perfect. Many AI companies shy away from these industries in favor of more general, qualitative tasks where there is a lower accuracy threshold but also potentially less value to users.
Breaking through the cold-start problem
At Arc, we’re committed to building software for finance professionals, and thus acutely aware of the biggest pain points still faced by our customers in their work. In particular, when underwriting deals, lenders spend dozens of hours a week analyzing files, building Excel models, and writing diligence memos—valuable yet manual and time-consuming work that slows down dealmaking.
By listening to our customers, we’ve taken a different approach to AI than others. We’re focused on depth over breadth, zeroing in on one industry vertical—the $2 trillion private credit industry. In doing so, we have overcome the cold start problem through our domain expertise, unlocking high accuracy levels with even the most complex tasks (e.g., financial analysis) and bringing more value to our users. The following chart explains how Arc’s approach differs from others in the market:
 Arc focuses on the highest priority tasks for private credit users. The vertical focus and embedded knowhow from Arc Capital Markets enable Arc to deliver highly accurate results, even with more complex tasks (e.g., financial analysis).
Arc focuses on the highest priority tasks for private credit users. The vertical focus and embedded knowhow from Arc Capital Markets enable Arc to deliver highly accurate results, even with more complex tasks (e.g., financial analysis).
Over the past two years, our engineering and finance teams have closely collaborated to build Arc Intelligence, an AI platform designed to equip credit investors with modern decision-making tools. Today, credit investors access these automation tools within Arc Capital Markets (ACM), our $4 billion private credit marketplace processing billions in loan volume that launched in January 2024. The combined platform exists to help connect hundreds of private credit lenders to companies on Arc's platform, making transactions more efficient.
Arc Capital Markets serves as an ideal environment to build and refine the Arc Intelligence platform. Credit applicants provide robust virtual data rooms with unstructured financial and business data—spreadsheets, PDFs, and presentations. On the other side, credit firms complete standardized workflows before making underwriting decisions, which include creating a range of internal memos. By integrating Arc Intelligence within Arc Capital Markets, we’re able to leverage the knowhow generated on the platform to improve our model’s accuracy, which in turn drives dealmaking efficiency. As depicted below, the result is a flywheel where each side accelerates performance in the other.
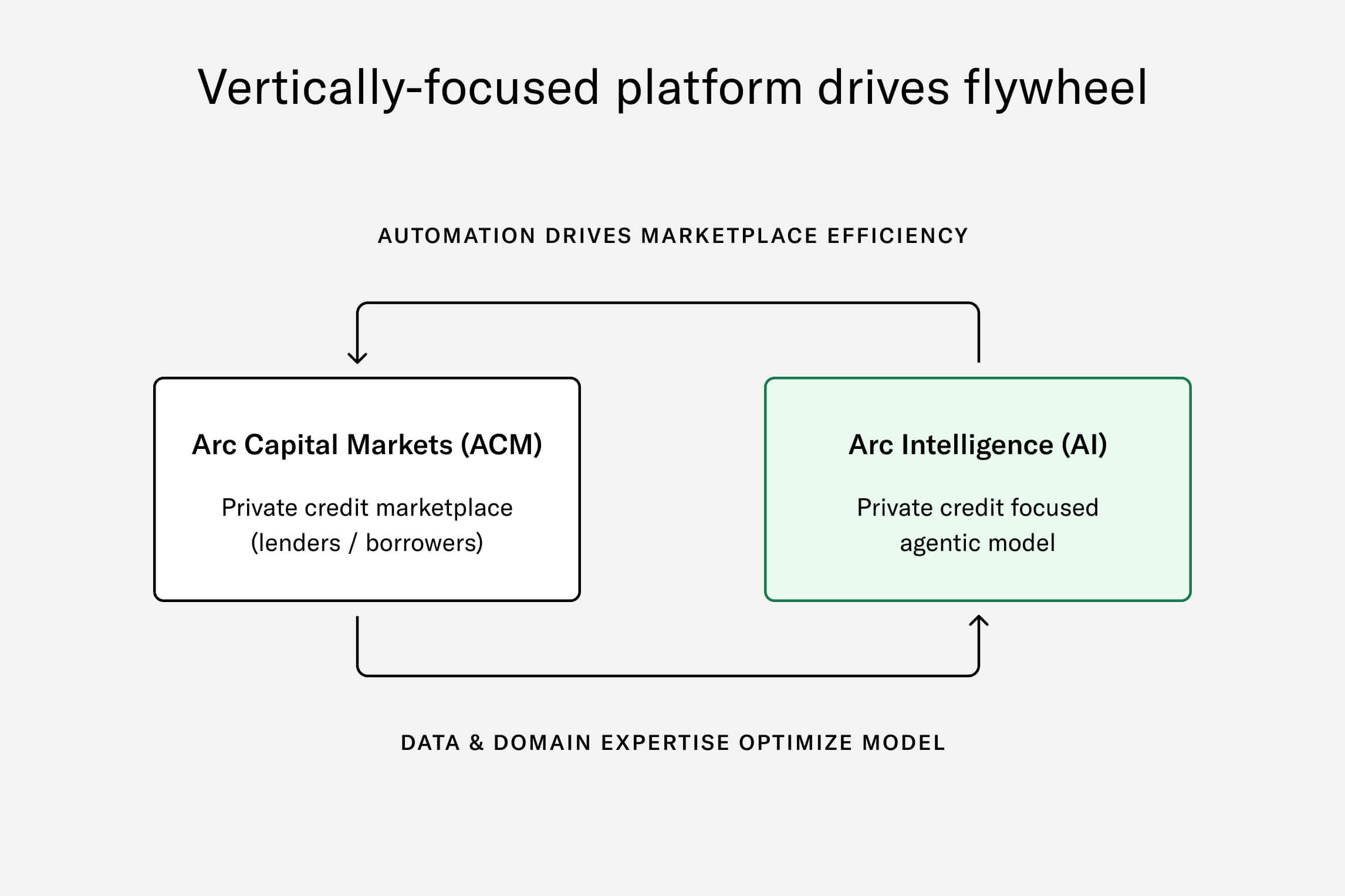 Combining Arc Capital Markets and Arc Intelligence creates a strong feedback loop leading to greater model accuracy and marketplace efficiency.
Combining Arc Capital Markets and Arc Intelligence creates a strong feedback loop leading to greater model accuracy and marketplace efficiency.
How it works: agentic AI for finance
Arc Intelligence is an agentic system that autonomously completes complex financial analysis tasks. It plans its actions, executes them using tools, and employs feedback loops to revise its approach until it reaches a final outcome.
To understand what agentic means, consider the analogy of solving a math problem. A non-agentic system attempts to solve it in a single step—zero-shot solving—without prior planning or breakdown. In contrast, an agentic system plans the solution, breaks it into manageable steps, utilizes tools like a calculator, and verifies the result.
A simplified, high-level view of our agentic workflow is shown in the figure below. In this setup, a coordinator agent examines the task and creates an initial plan outlining the necessary steps. It then assigns subtasks to specialized agents—each equipped with relevant tools and tailored prompts—to handle specific aspects of the work.
Some agents are optimized to process quantitative data, such as customer revenue or invoices, while others gather qualitative insights like the company's revenue model. These agents apply their reasoning skills and utilize available tools to complete their designated tasks.
As the process unfolds, the coordinator agent receives feedback on progress, allowing it to revise the initial plan or adjust the approach as needed. When the task is completed—assuming the necessary data is available—the coordinator agent assigns a confidence score to the result. If the outcome is less than ideal, it may label the result as "needs user review" or choose not to provide an answer, offering an explanation.
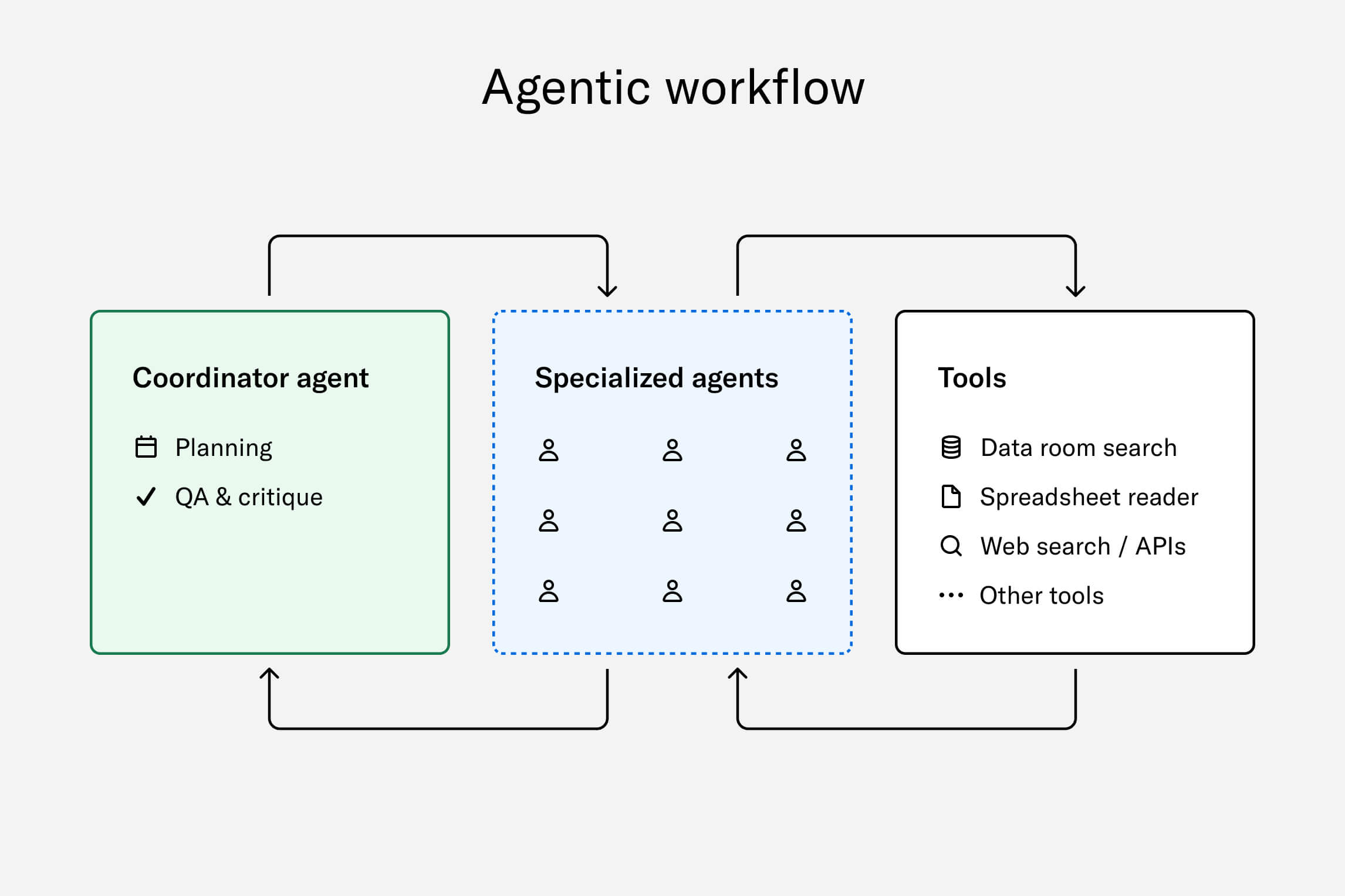 High level view of Arc Intelligence agentic workflow.
High level view of Arc Intelligence agentic workflow.
While the agentic architecture enhances orchestration and reasoning capabilities, producing high-quality outputs and precise calculations requires building specialized tools and an evaluation framework to benchmark the system.
Building specialized tools
Just as software developers gain significant productivity from tools like Integrated Development Environments (IDEs), LLMs also benefit from specialized tools that enhance their capabilities. While LLMs are powerful in interpreting language and code, their performance is greatly improved when equipped with tools designed for specific tasks. For instance, when working with unstructured documents, specialized tools enable LLMs to achieve substantial improvements in efficiency and accuracy.
Building on this concept, Arc Intelligence utilizes proprietary tools we've developed in-house, giving it unique capabilities in performing financial analyses relevant to private credit. Central to our system is the LLM-assisted Retrieval-Augmented Generation (RAG) tooling, which helps agents search and navigate complex data rooms by identifying all relevant sources needed to complete a task. For example, when conducting a financial analysis requiring data from the past two years, our system compiles relevant sections from multiple Profit and Loss (P&L) statements covering the target periods. Similarly, when tasked with gathering information about a company's business model, it can extract data from the pitch deck, company website, and financial statements.
Another important toolset is for spreadsheet understanding, which leverages a specialized encoding format. Extracting information from freeform spreadsheets poses significant challenges due to inconsistent formats and large data volumes. By compressing spreadsheets to 10–15% of their original size, our encoding method optimizes them for efficient processing. The reader agents—which operate through agentic flows—enable data extraction with near-perfect precision. Combining this toolset with agentic document understanding enables seamless handling of spreadsheets containing tens of thousands of cells, with an almost zero error margin.
Creating an evaluation framework
Over our two years of developing the Arc Intelligence platform using foundation models, we've learned that adopting a process similar to Test-Driven Development (TDD) is crucial. TDD involves writing tests before developing functionality to ensure the code meets specific requirements. Likewise, achieving high-accuracy outputs from AI models necessitates assembling comprehensive test datasets upfront. The more test cases we add, the more we uncover potential shortcomings, allowing us to address them proactively.
Optimizing models and prompts is a meticulous process. It's easy to focus on a single example and tweak the approach extensively, but this can lead to overfitting—where the model performs exceptionally on that example but poorly on others. Overfitting reduces the model's generalizability and can compromise its effectiveness in real-world applications.
To ensure a productive process, we've established close collaboration with our in-house team of private credit veterans. These veterans help curate and develop datasets that reflect real-world scenarios in private credit. One of our internal Objectives & Key Results (OKRs) tracks the number of datasets prepared by this team. Each week, we incorporate new datasets based on insights from ongoing projects and feedback from our partner lenders.
We have developed an in-house, LLM-assisted evaluation suite that tests each task against our datasets. The suite assigns scores based on how closely the model's outputs align with ideal or expected answers, considering metrics like accuracy, relevance, and completeness. For any score that falls short of our high standards, we conduct a manual review to assess the model's performance and identify areas for improvement. This thorough evaluation process helps ensure that our models consistently meet the stringent demands of private credit analysis.
How we track accuracy
Our model evaluation process involves running each task multiple times across various datasets to identify and prevent potential regressions—instances where the model's performance deteriorates on previously successful tasks. Below, we share three sample tasks and compare our capabilities against the state-of-the-art GPT-4o model, which we equipped with a Retrieval-Augmented Generation (RAG) tool for reading data room files.
 Sample tasks and comparison vs. GPT-4o. “Check” represents >99% accuracy across tasks with high confidence label; “dotted check” represents impractical accuracy (<50%); “cross” represents unreliable accuracy (<20%).
Sample tasks and comparison vs. GPT-4o. “Check” represents >99% accuracy across tasks with high confidence label; “dotted check” represents impractical accuracy (<50%); “cross” represents unreliable accuracy (<20%).
We carefully selected tasks above that represent distinct capabilities of our model. Achieving high accuracy rates in these tasks enables us to expand more easily into similar or adjacent tasks that require comparable competencies. For example, the task "Total cash balance" seems simple; however, completing it with perfect accuracy requires analyzing multiple documents and their respective "as of" dates, identifying the most recent period, and precisely extracting the numerical value.
In our benchmarks, the model currently completes 96% of the tasks with a "high confidence" label—meaning they do not prompt user review—and achieves over 99% accuracy across all tasks within this category. As the capital marketplace continues to grow, we will expand our suite of tasks available to users, ensuring they meet our stringent accuracy targets.
To learn more and sign up, visit Arc Intelligence.
Acknowledgments
Emre Kazdagli created Arc Intelligence’s benchmarking framework and wrote this blog post, in collaboration with Nick Lombardo. Alp Artar, Francisco Claude-Faust, Samuel Leadley, Aiqi Liu, Jack Jenkins, Lyndon Vickrey, and many others have contributed to building and optimizing Arc Intelligence.